Having never used a paid VPN provider before, I decided to take advantage of TorGuard’s current 50% off lifetime offer to see what one is like. Apparently TorGuard is reasonably well respected and widely used, so I wasn’t really expecting to be disappointed; so plonked down 6 months’ payment (since they give no further discounts for yearly payments – just a free email account which is of no interest to me).
Pre-ordering
They seem to skimp a little on details – I couldn’t find a list of server locations, beyond the flags list they have on their order page. There’s a mention in the FAQ to find the list of servers in your account, which isn’t terribly useful if you want to run ping tests to check latency to their servers.
After ordering, I did find that there is a list of countries on the order page, at the bottom after clicking the “COUNTRIES” link – since I was Ctrl+F’ing for “location”, I missed that. Oops, but they could’ve made the list easier to find. Still, there’s no hostnames/IPs that you can lookup and test.
They sell both VPN and proxy services, as well as a bundle (VPN+proxy), but trying to order a bundle just sends you to the same page as ordering a proxy (although the cart ID is different?). However, the previous blog post seems to mention that the VPN service includes proxies… Confusing, but after ordering, it seems that this is indeed true, despite the proxy service not being advertised in the VPN features listing.
Also their website is proxied through CloudFlare, meaning that you get stuck in a redirect loop trying to access it until you enable cookies and Javascript. I would’ve expected a privacy serious service to be less reliant on 3rd party services (which may or may not keep logs or be complicity to US interests, since CF is US based), but oh well.
Ordering
Overall, fairly straightforward and standard process. There’s a checkbox for “TG Viscosity”, which, after a bit of searching, turns out to be a free license to a VPN client they provide, but it would help to at least put a few words to explain what it is.
Pricing on their dedicated IP option seems whack – they as for US$8 recurring regardless of your selected billing period, which presumably means $8/month if you pay monthly, or $8/6 months if you pay semi-annually? Interestingly, the price is different if you select annual payment (US$55/year). Probably a bug/oversight somewhere.
I paid via credit card, and they ask the usual name + billing address (this is not asked for other payment methods) as you’d expect. However, they seem to require a phone number, which I believe isn’t necessary for CC payments. I entered a junk value here and it seemed to be accepted fine anyway. It’s nice that they give you the option whether to store the CC details for recurring payments or not.
The ToS seems to be fairly standard as expected, including terms expressly forbidding the service to be used for various illegal activities that I expect many VPN users would explicitly use it for anyway.
After payment, you get redirected through to download their software, which should probably be the easiest way to get the VPN up and running.
Services
After registering, I found that neither VPN nor proxies worked (couldn’t authenticate it seems). Put in a support ticket, to which they responded in a matter of minutes. Apparently my using an email address with a ‘+’ in it causes issues, which they fixed by removing it. (Gmail and Hotmail use ‘+’ for email aliases)
VPN
In your account, you can see the list of locations (copy posted below) supported, although clicking on the “1250 servers” link definitely doesn’t show you a list of all the servers.
After installing the VPN client provided by TorGuard, you get a fairly simple and straight forward interface, which seems to address the concerns that I’d expect most users to have. The server list here is somewhat nicer than the one listed in your account as it breaks things down by cities instead of just countries, but no hostname/IP provided, so you have to go testing them yourself to figure them out. Still nowhere in the range of 1250 entries though (and if they have multiple servers per location as one might expect, there’s no indication of how many are there, bandwidth availability etc).
They seem to support the standard VPN protocols, however, SSTP support is limited to only a few locations – something which I would imagine shouldn’t be too difficult to support on all their servers. It seems like OpenVPN supports connecting over a HTTP proxy though, which I suppose could be an alternative to cases where you’d need SSTP – still, they should support all protocols at all locations IMO.
(as someone who has never set up a VPN server, I don’t know the limitations of needing to support this stuff, so there’s maybe reasons behind this)
From posts I’ve read, some nice things they support, that various other services don’t, include multiple VPN connections and port forwarding. I can’t seem to find the port forwarding option though, apart from an announcement which points you to unavailable options. Maybe I’ll ask support if I ever need it.
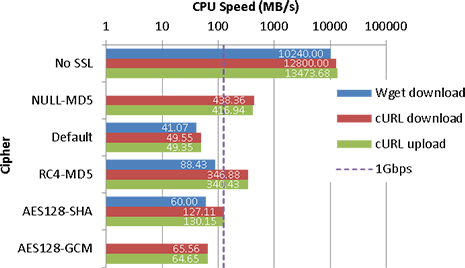
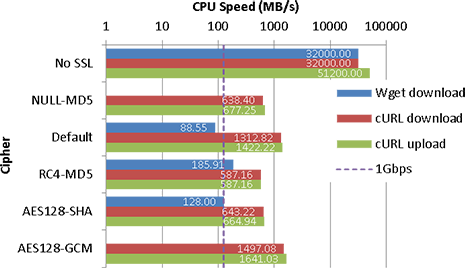
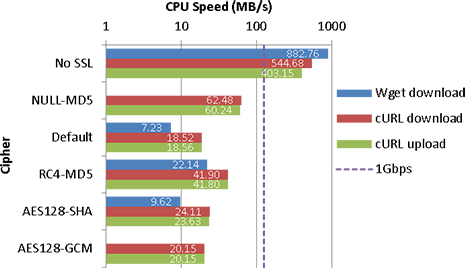
I’ve otherwise done minimal testing of the VPN and no speed/latency tests at this stage.
Proxy
Disappointingly, many of the VPN servers don’t support HTTP/SOCKS proxies (see list below). Seems like something that should be easy to support, in fact, I imagined that they’d have the same locations for both before ordering. Whilst it’s possible to set up a VM with a HTTP/SOCKS server running over the VPN, it’s somewhat of a convoluted setup which they should be doing instead (I haven’t looked into whether it’s possible to use routing rules to bypass the need for a VM, but a HTTP/SOCKS server which can speak over a specific interface would still be necessary).
It does seem to match the list of countries mentioned on their proxy info page, so the VPN service is actually bundling their complete proxy service as opposed to some watered down version.
Anyway, I decided to give a SOCKS server a go. Presumably they need authentication, although no instructions are given on the listing page. Attempting to use them without authentication indeed doesn’t work. Unfortunately Firefox doesn’t support SOCKS proxies with auth, so I tested PuTTY, using the registered email address and password instead, which seemed to work as expected (after I had my username changed due to it containing a ‘+’).
TorGuard doesn’t support SSH tunneling unfortunately – it would be nice to have an encrypted non-VPN proxy (SSH tunneling may also offer stuff like reverse port forwards, though this may be problematic with a shared IP).
DNS
TorGuard provides its own DNS resolvers (91.121.113.58 and 91.121.113.7) although they don’t mention why one should use them. As DNS isn’t authenticated, I suppose anyone could use the resolvers.
The resolvers don’t appear to be anycast routed, don’t support DNSSEC validation and have no IPv6 address, so there doesn’t really seem to be any reason to use them over public resolvers like Google DNS or OpenDNS (unless you don’t trust those companies). I suppose one may question the logging performed by public resolvers, but supposedly this should be less of a concern if you’re using a VPN. The only other thing I can think of may be if you’re concerned with the initial connect to the VPN, since TorGuard gives you hostnames rather than IP addresses, it may be possible to correlate resolver logs to your IP connecting to a particular VPN server…
Certificate
There’s a “TG Certificate” link, which, when clicked, attempts to install a root cert to your browser. Don’t know what this is for (SSTP perhaps? have personally never used it so am clueless) – so it could be useful to have an explanation. After a bit of a search, a KB article suggests that it may be for OpenVPN.
Apps
They seem to have their own apps for all the major platforms (Windows/Mac/Linux x86), including Android, which shows they went to a bit of effort to make things easy in that regard. Lack of an iOS app is understandable (can still just use regular OpenVPN there).
I haven’t really bothered testing the apps, so no comment there. I also haven’t tried the Viscosity client yet either.
Conclusion
As I haven’t done much testing at this stage, I can’t make much of a conclusive remark yet, but TorGuard’s basic VPN service seems to offer more or less what you’d expect. It’s difficult to recommend them as a proxy service though, with the limited locations they provide.
Their listing of locations needs to be improved – should be more accessible and provide more details (city and transit provider would be nice (I know you can get these details yourself, 1 by 1)), as well as provide a more complete listing for users who do not wish to use the official client. I haven’t tried just using IPs of VPN endpoints from the official client in other VPN clients yet, which I suppose could work, but you shouldn’t need to have to do this.
The standard monthly pricing (US$10/month) seems quite overpriced compared to other VPN providers and even at US$5/month, paid semi-annually seems a bit of a stretch. US$2.5/month, the price after the 50% discount is somewhat more palatable to me.
Of course, a cheap US$10/year VPS can provide a lot more flexibility/functionality than most VPN services, provided you can set things up yourself and only need one location. Heck, if you’re just someone who needs a US VPN for streaming video, you can do it for free. VPNGate also seems to be a nice free VPN service, although I’ve not tested it for anything beyond web browsing.
For me personally, it was the niche locations that I wanted to have access to, where servers are typically hard to get and/or expensive (like Australia).
Considering the effort gone into the apps, the somewhat extensive knowledge base of guides (which, sadly, lacks a search feature) and the quick support responses, TorGuard does seem to be quite friendly to beginners and those less technically inclined (who probably don’t care so much about knowing hostnames/IPs etc).
tl;dr: seems to be okay, a bit expensive (unless you get 50% off) and nothing really seems to stand out. I haven’t tried other services for comparison though.
Update (19th Dec 2015)
I’m nearing the end of the 6 month subscription now, and I won’t be renewing the service. I primarily use the Australian servers (TorGuard provides two – one in Sydney and one in Melbourne) for low ping and minimal speed penalty with using a VPN. The service has been fine and speeds are pretty good, but there’s one annoying problem:
TorGuard forces OpenDNS on the Australian servers. By ‘force’, I mean they redirect all UDP port 53 traffic to OpenDNS, which makes it impossible for one to use their own DNS server. Support does not provide any workaround (I suggested forcing to Google’s DNS instead but they wouldn’t do it) and claims that this is due to Australia implementing internet filtering (which, at the time of writing, is not true). Ironically OpenDNS does perform its own filtering (e.g. kat.cr is intercepted). In my opinion, this forced redirect shouldn’t be necessary – DHCP can suggest DNS servers, and/or these servers could be configured by their VPN software, enabling more advanced users to override the choice of DNS server if necessary. Furthermore, it is unknown whether Australia’s new mandated ISP filtering policy will be DNS based, since it has yet to be implemented, meaning that a DNS override may be unnecessary.
Support, whilst they respond fast, don’t always show much technical competence. I get that tickets get handled mostly by lower level support before being escalated, but it does mean that technically advanced users may need some back & forth to get what you need.
Overall, my main complaint is the forced DNS redirect on Australian servers, which, unfortunately, is a deal breaker for me. If this isn’t an issue for you, TorGuard seems to be a fine service otherwise.
Continue reading →